In this article i'll show you how to forward events to private containers using serverless services and fan-out pattern.
I'll explore possible solutions within AWS ecosystem, but all are applicable regardless the actual service / implementation.
Context
Suppose you have a cluster of containers and you need to notify them when a database record is inserted or changed, and these changes apply to the internal state of the application. A fairly common use case.
Let's say you have the following requirements:
The tasks are in an autoscaling group, so their number may change over time.
A task is only healthy if it can be updated when the status changes. In other words, all tasks must have the same status. Containers that do not change their status must be marked as unhealthy and replaced.
When a new task is started, it must be in the last known status.
Status changes must be in near real- time. Status changes in the database must be passed on to the containers in less than 2 seconds.
Given these requirements, let's explore a few options.
Option 1: tasks directly querying the database
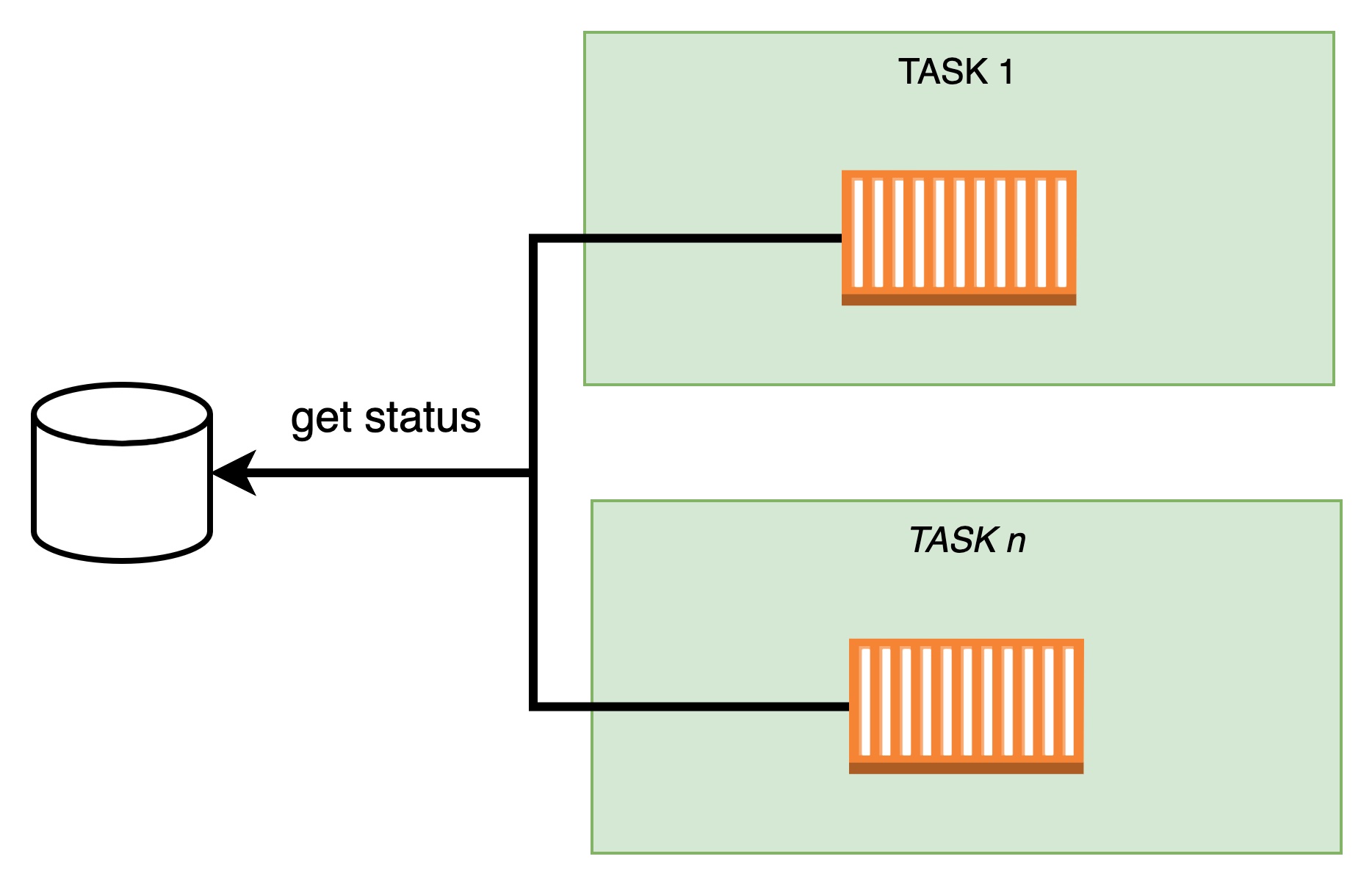
Pros:
easy to implement: The task is just to perform a simple query and get the current status, assuming it can be queried.
fast: It really depends on the DB resources and the complexity of the query, but there are not many hops and can be configured to be fast. You can configure polling time to match our requirement of 2 seconds requirement, e.g. every 1 second.
easy to mark as unhealthy tasks that fails to perform queries. The application could catch errors in queries and mark itself as unhealthy if it has enough resources. Otherwise, the load balancer's health check would fail.
Cons:
waste of resources: Your application queries the database even if no changes have been made. If your database does not change more frequently than the polling rate, most queries are useless.
your database is a single point of failure: If the database cannot serve queries, tasks cannot be notified.
it does not scale well: As the number of tasks grows, the number of queries grows and you may need to scale the database as well, or you may need a very large cluster running all the time to accommodate any scaling, wasting resources.
difficult to monitor: How can you check if an individual task is in the right state?
In such a scenario, I definitely don't like polling.
Let's try a different and opposite approach.
Option 2: Db streams changes to containers
Instead of having tasks asking to the database, let's have the database notifying them for changes.
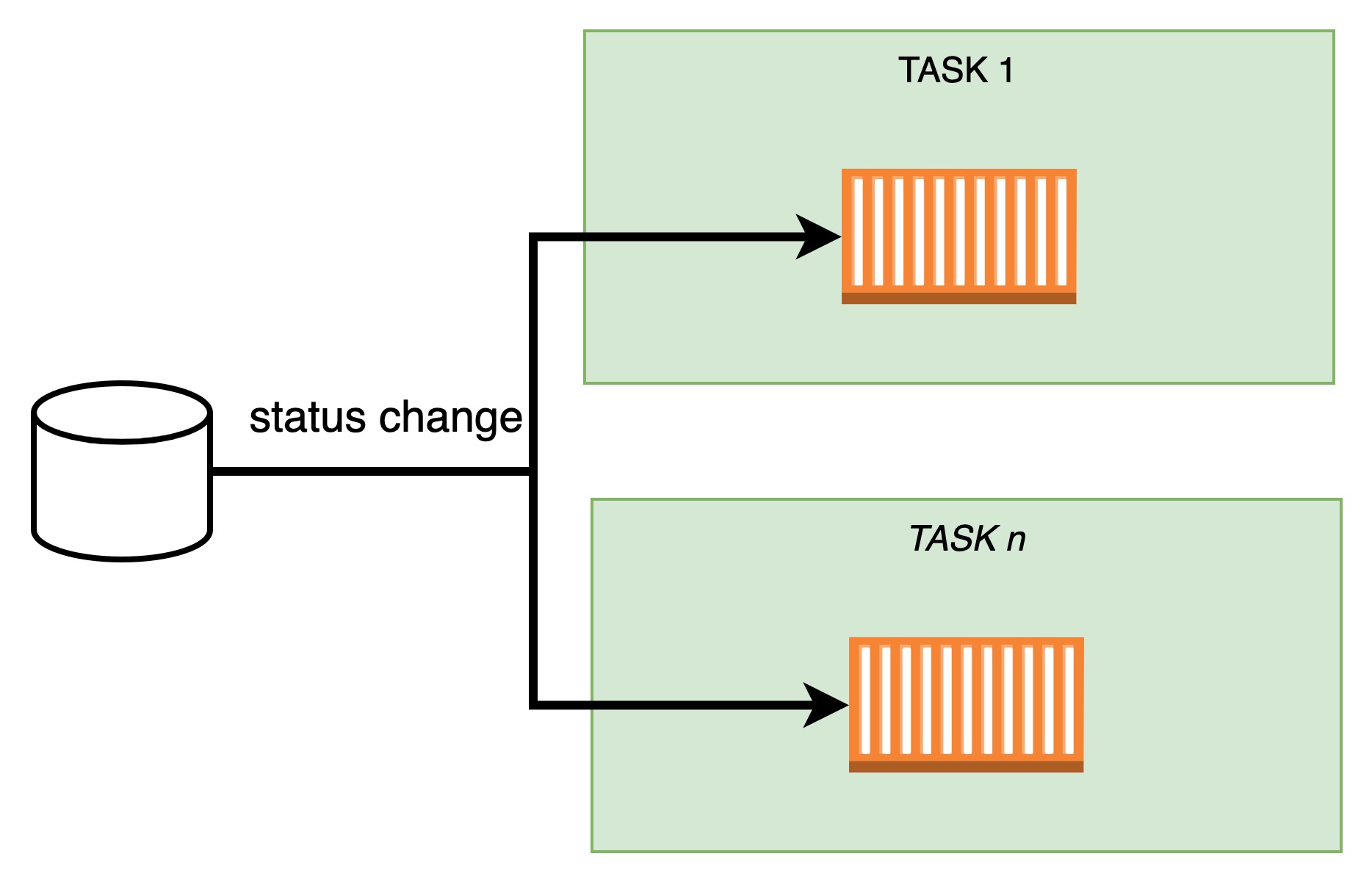
Before go into the pros and cons, i must say that it would be very hard if not impossible to implement this solution exactly as i drown it. We can use a very popular pattern, called fan-out.
This is the wikipedia definition:
In message-oriented middleware solutions, fan-out is a messaging pattern used to model an information exchange that implies the delivery (or spreading) of a message to one or multiple destinations possibly in parallel, and not halting the process that executes the messaging to wait for any response to that message
To make things a little more concrete, let's use some popular AWS services that are commonly used to implement this pattern:
The solution looks like this:
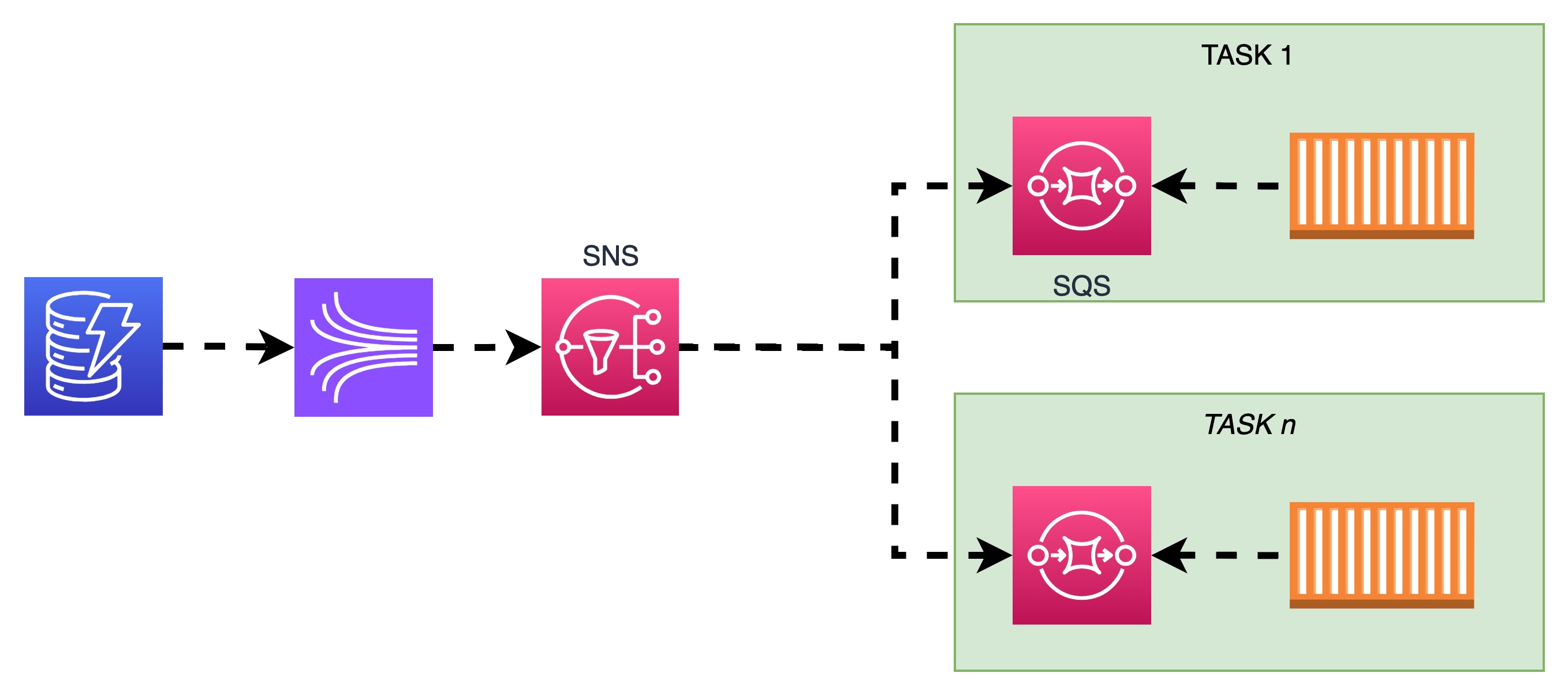
Now let's explore pros and cons:
Pros:
first of all, you can see that arrows turned into dotted lines. This architecture is completely asynchronous
easy to implement: all integrations you need are native. You need just to configure serverless services and to implement a SQS consumer in your application.
very scalable: you can add as many task as you want without affecting the database, your limit here is SNS but is very high. As stated in official docs a single topic supports up to 12,500,000 subscriptions.
no waste of resources: a.k.a really cost-effective. This solution leverages on pay-per-use services, and they would be used only when actual changes occurs on db.
very easy to monitor: both SNS and SQS supports Dead Letter Topic / Queue: if a message isn't consumed within the timeout, it can be moved into a DLQ. You can set up an alarm if a DLQ is not empty, and kill the associated task.
easy to recover: If a container cannot consume a message, it can try again. In other words, it does not have to be online and ready to receive the message at the moment it is delivered, as the queues are persistent.
very fast: i did a benchmark on this solution, here the github repo with the actual code. Later on in this article we'll see results
Cons
more moving parts: even if the integration code is not required since it's provided by AWS, connecting things and tuning connections is not straightforward as performing a query.
not so easy to troubleshoot. As every distributed system, i would say.
it strongly depends on serverless services: if one link in the chain slows down or are not available, your containers can't be notified. We have to say that all involved services have a very good SLA: 3 nines for SQS and SNS and 4 nines for DynamoDB. Not sure about Dynamo stream, since it appears to be not included in DynamoDB SLA. I suppose dynamo streams are backed by Kinesis Streams, which also has 3 nines of availability.
Open points:
The main open point here, to me, was: is this fast enough? Let's verify it.
Trust, but verify
I couldn't find any official SLA about latency for involved services nor any AWS official benchmark.
So i decided to perform one myself, and i scripted a basic application using typescript and CDK / SDK.
Here the github repo with the actual code and details on how the system is implemented.
Before going ahead, bare in mind that i performed this benchmark with the goal to understand if this combination of services / configuration could fit for my specific context / use case. Your context may be different, and this configuration may not fit with it.
System design and data flow

The AppSync API receives mutations and stores derived data in the DynamoDB table
The DynamoDB stream the events
The Lambda function is triggered by the DynamoDB stream
The Lambda function sends the events to the SNS topic
The SNS topic sends the events to the SQS queues
The Fargate service reads the events from the SQS queues
If events are not processed within a timeout, they are moved to the DLQ
A Cloudwatch alarm is triggered if the DLQ is not empty
Key system parameters:
Region: eu-south-1
Number of tasks: 20
Event bus: 1 SQS per task, 1 DLQ per SQS, all SQS subscribed to one SNS
SQS Consumer: provided by AWS SDK, configured for long polling (20s)
Task configuration: 256 CPU, 512 Memory, Docker image based on Official Node Image 20-slim
DynamoDB Configured in PayPerUseMode, stream enabled to trigger Lambda
Lambda stream handler written in node20 bundled with ESBuild, configured with 128MB
Benchmark parameters
I used a basic postman collection runner to perform a mutation to Appsync every 5 seconds, for 720 iterations.

Goal
The goal was to verify if containers would be updated within 2 seconds.
Measurements
I used the following Cloudwatch provided metrics:
Appsync latency
Lambda latency
Dynamo stream latency
and I created two custom metrics for measuring SQS and SNS time taken.
Time-taken custom metrics are calculated from the SNS and SQS-provided attributes:
The time (GMT) when the notification was published.
returns the time the message was first received from the queue (epoch time in milliseconds).
Returns the time the message was sent to the queue (epoch time in milliseconds).
The following code snippet shows you how attributes are used to calculate sns time taken in millis and sqs time taken in millis
let snsReceivedISODate = messageBody.Timestamp;
if (snsReceivedISODate && message.Attributes) {
clientReceivedTimestamp = +message.Attributes.ApproximateFirstReceiveTimestamp!;
sqsReceivedTimestamp = +message.Attributes.SentTimestamp!;
let snsReceivedDate = new Date(snsReceivedISODate);
snsReceivedTimestamp = snsReceivedDate.getTime();
clientReceivedDate = new Date(clientReceivedTimestamp!);
sqsReceivedDate = new Date(sqsReceivedTimestamp!);
snsTimeTakenInMillis = sqsReceivedTimestamp - snsReceivedTimestamp;
sqsTimeTakenInMillis = clientReceivedTimestamp - sqsReceivedTimestamp;
i didn't calculate the time taken by the client to parse the message because it really depends on the logic the client applies to parsing the message.
Results
Disclaimer: some latency measurements are calculated on consumers' side, and we all know that synchronizing clocks in a distributed system is a hard problem.
Still, measurements are performed by the same computing nodes.
Please consider following latencies not as precise measurements but as coarse indicators.
Here screenshots from my Cloudwatch dashboard
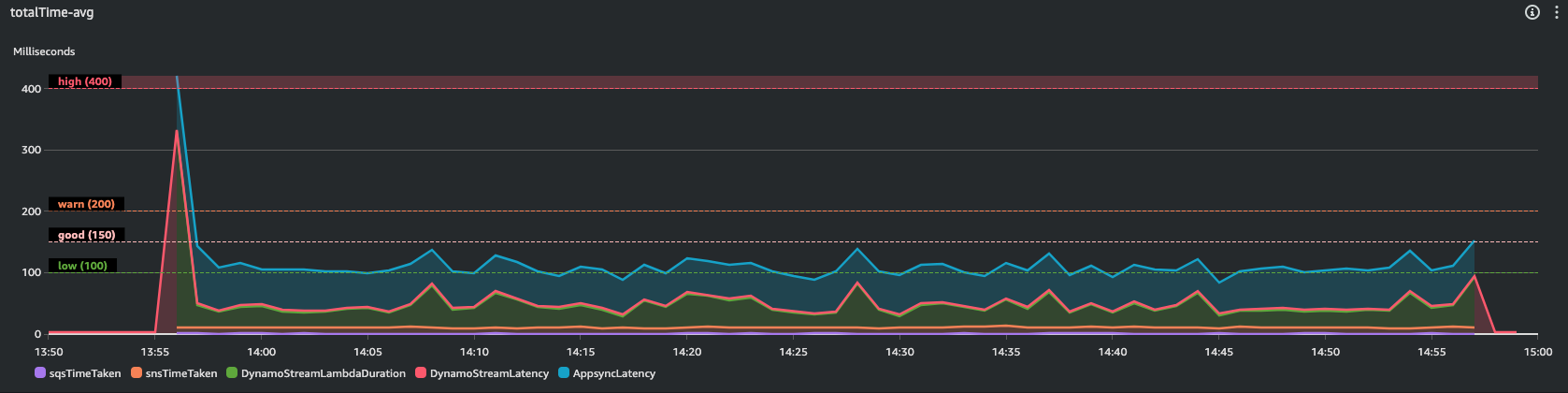
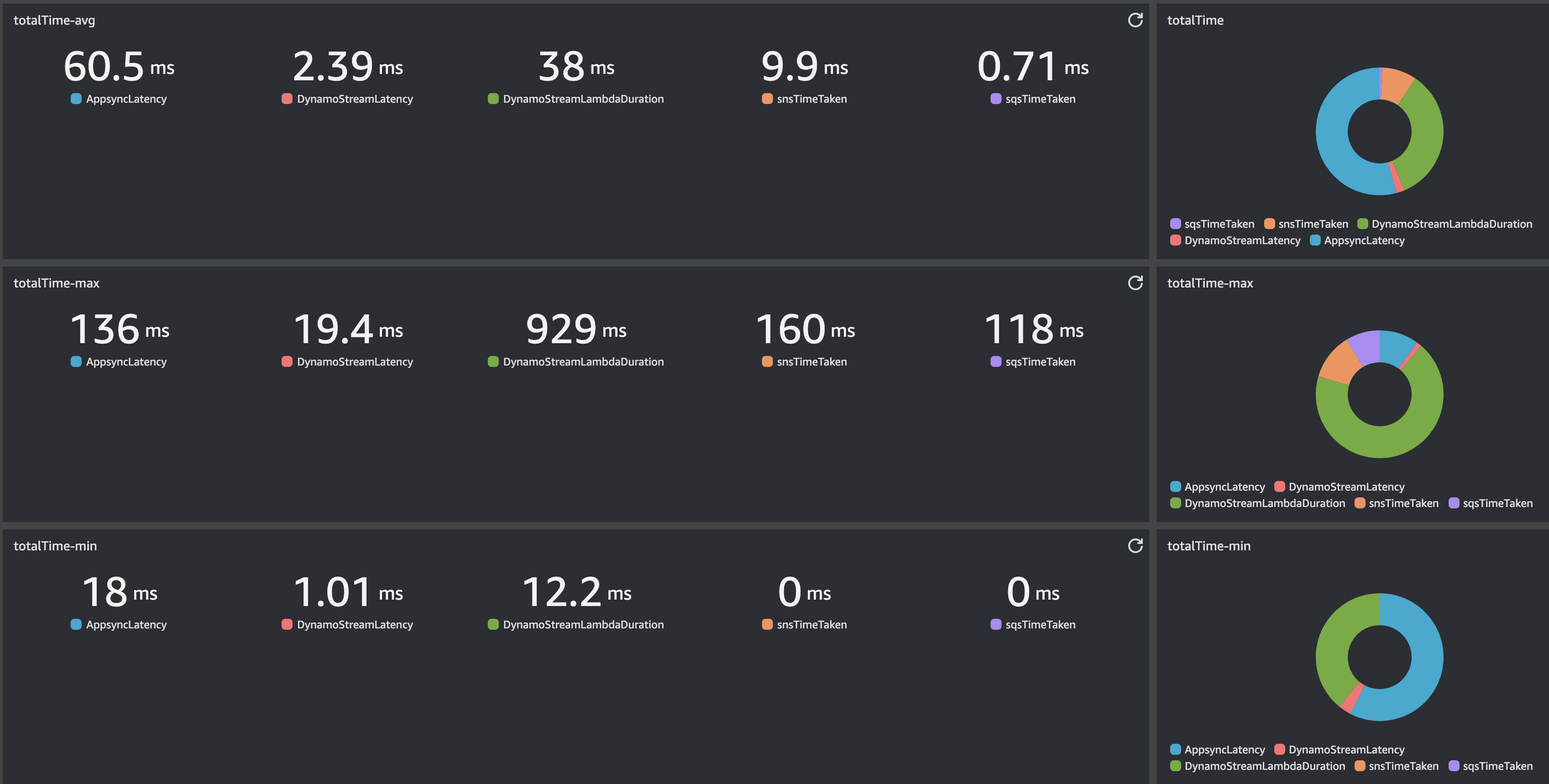
Few key data, from Average numbers:
Most of time is taken by Appsync, i couldn't do anything to lower this latency since i used native Appsync native integration with DynamoDB.
The only custom code is the Lambda stream processor code, and lamba duration is the second slowest component here. As you can see in the graph, the lambda cold start is the killer, but considering this we can observe a very good latency on avg (38 ms).
The average total time taken is 108.39 ms
The average response time measured by my client, that cover my client network latency, is 92 ms. Given Appsync AVG Latency is 60.5 ms, my Avg network latency is 29.5 ms. This means that from my client sending the mutation to consumers receiving the message there are 108.39 + 29.5 = 137.89 ms
Conclusion
This solution has proven to be fast and reliable and requires little configuration to set up.
Since almost everything is managed, there is little space for tuning and improvements. In this particular configuration, I could simply give the Stream Processor Lambda more memory, but memory and latency do not scale (inversely) together.
I could remove Lambda and replace it with Event Bridge Pipe. I haven't tried it yet, but i'm going to use the exact same benchmark and compare the results.
UPDATE: here the benchmark of the aforementioned solution with EventBridge
Last but not least, keep in mind that AWS does not always include latency in the service SLA. I've run this benchmark a few times with comparable results, but I can't be sure that I will always get the same results over time. If your system requires stable and predictable performance over time, you can't go with services that don't include performance metrics in their SLA. You're better off taking control of the layers below, which means you should consider going to a restaurant or even making your own pizza at home.
Wrap up
In this article, I have presented you with a solution that I had to design as part of my work and my approach to solution development: this includes clarifying the scope and context, evaluating different options and having a good knowledge of the parts involved and the performance and quality attributes of the overall system, writing code and benchmarking where necessary, but always with the clear awareness that there are no perfect solutions.
I hope it was helpful to you, and here is the GitHub repo to deploy both versions of the solution.
Bye 👋!