Evaluating Performance: A Benchmark Study of Serverless Solutions for Message Delivery to Containers on AWS Cloud - Episode 2
Another benchmark and more bonus code

I'm an old school developer, I started 20 years ago with Notepad as an IDE (?), then I worked as DevOps and for a few years now I've been working as a Principal Technical Architect. I'm interested in cloud computing and serverless architectures and love to dive deep into problems and find smart solutions.
This post follows my previous post on this topic, and it measures the performance of another solution for the same problem, how to forward events to private containers using serverless services and fan-out patterns.
Context
Suppose you have a cluster of containers and you need to notify them when a database record is inserted or changed, and these changes apply to the internal state of the application. A fairly common use case.
Let's say you have the following requirements:
The tasks are in an autoscaling group, so their number may change over time.
A task is only healthy if it can be updated when the status changes. In other words, all tasks must have the same status. Containers that do not change their status must be marked as unhealthy and replaced.
When a new task is started, it must be in the last known status.
Status changes must be in near real- time. Status changes in the database must be passed on to the containers in less than 2 seconds.
Solutions
In the first post about this i explored two options and measured performance of this one:
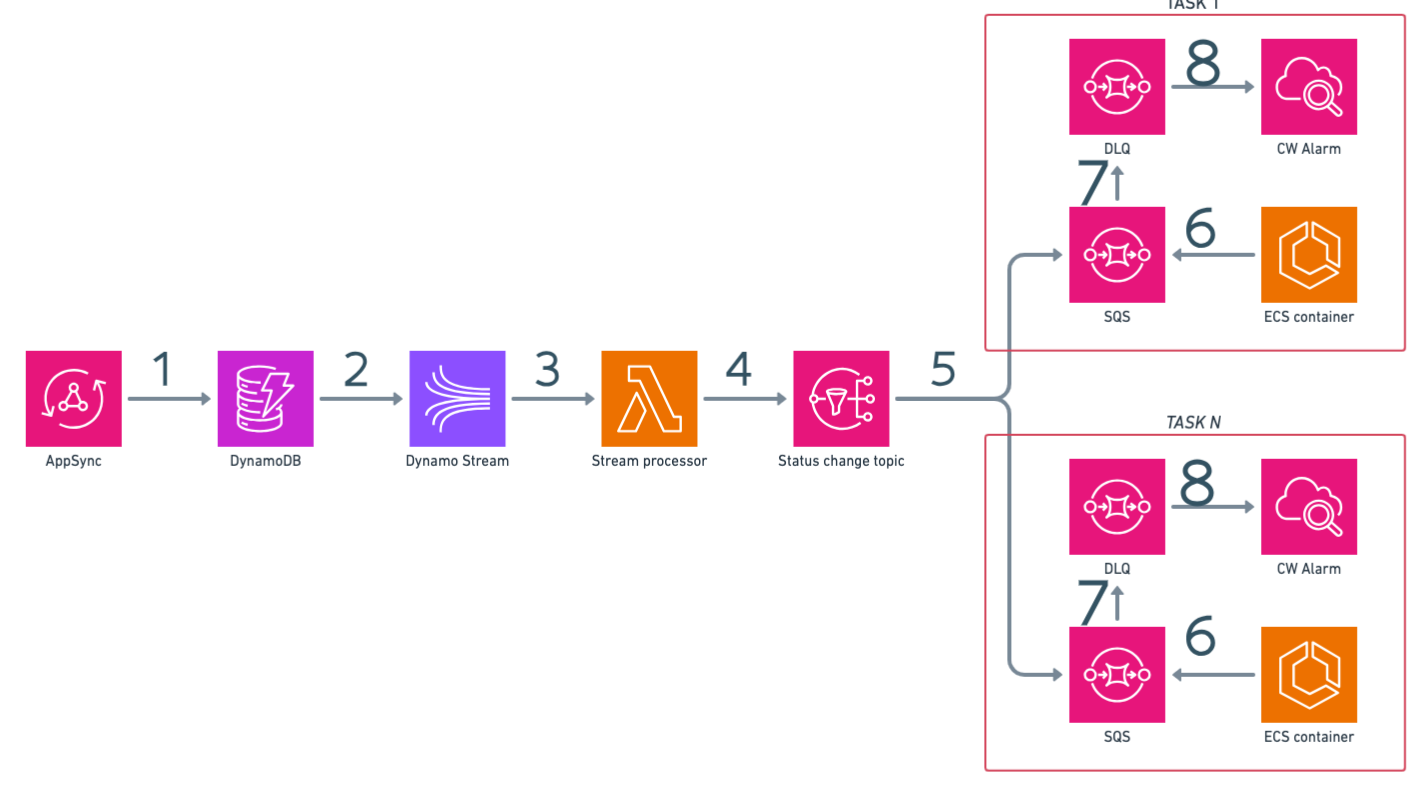
The AppSync API receives mutations and stores derived data in the DynamoDB table
The DynamoDB streams the events
The Lambda function is triggered by the DynamoDB stream
The Lambda function sends the events to the SNS topic
The SNS topic sends the events to the SQS queues
The Fargate service reads the events from the SQS queues
If events are not processed within a timeout, they are moved to the DLQ
A Cloudwatch alarm is triggered if the DLQ is not empty
The even more serverless version
An even more serverless version of the above solution replaces Lambda and SNS with Eventbridge
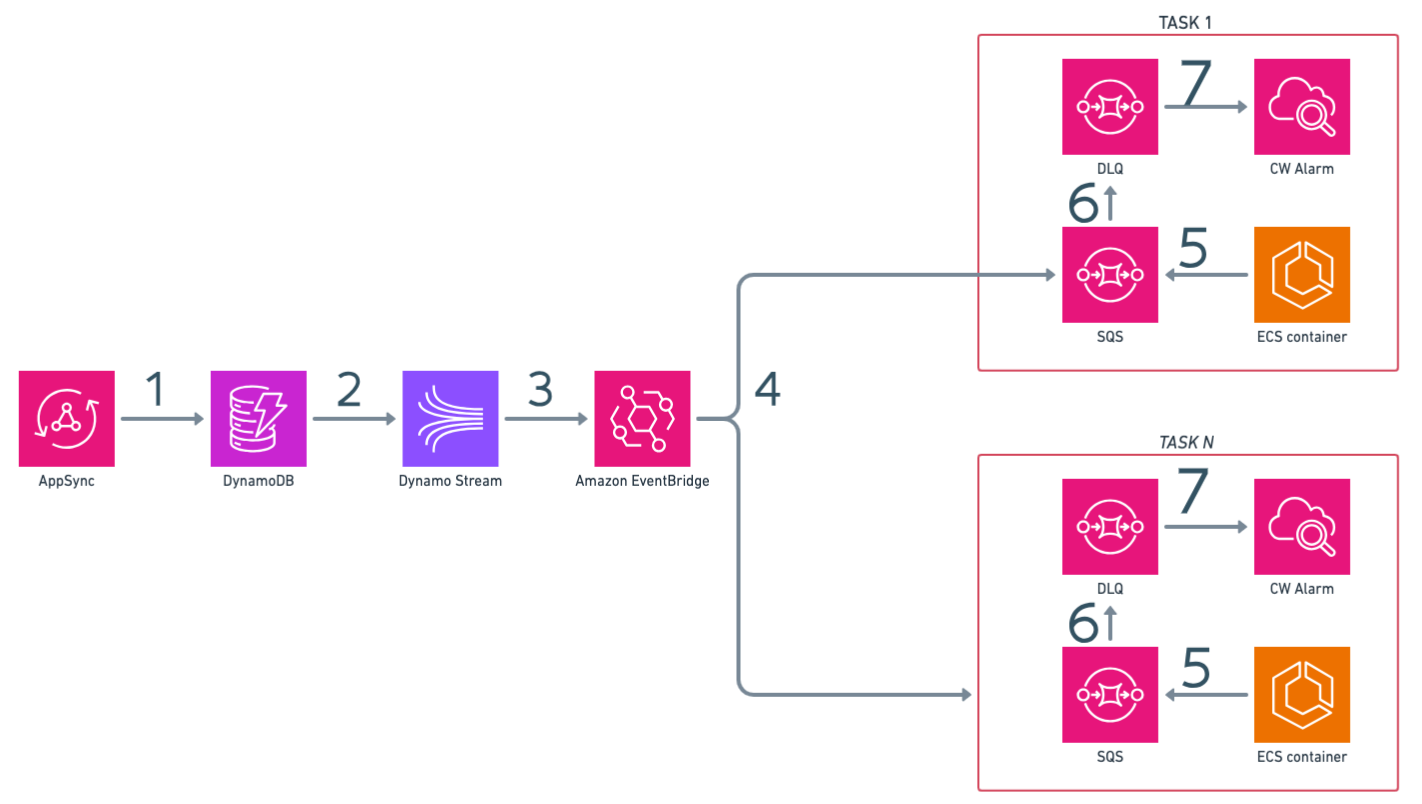
The AppSync API receives mutations and stores derived data in the DynamoDB table
The DynamoDB stream the events
EventBridge is used to filter, transform and...
...fan-outs events to SQS queues
The Fargate service reads the events from the SQS queues
If events are not processed within a timeout, they are moved to the DLQ
A Cloudwatch alarm is triggered if the DLQ is not empty
The only code i wrote here is the code to consume SQS from my application, no glue-code is required.
Trust, but verify
I've conducted a benchmark to verify the performance of this configuration, in terms of latency from the mutation being posted to Appsync to the message received by the client polling SQS.
Key system parameters
Region: eu-south-1
Number of tasks: 20
Event bus: 1 SQS per task, 1 DLQ per SQS, all SQS subscribed to one SNS
SQS Consumer: provided by AWS SDK, configured for long polling (20s)
Task configuration: 256 CPU, 512 Memory, Docker image based on Official Node Image 20-slim
DynamoDB Configured in PayPerUseMode, stream enabled
EventBridge configured to intercept and forwards all events from Dynamo stream to SQS queues
Benchmark parameters
I used a basic postman collection runner to perform a mutation to Appsync every 5 seconds, for 720 iterations.

Goal
The goal was to verify if containers would be updated within 2 seconds, and to verify performance against the first version.
Measurements
i used the following Cloudwatch provided metrics:
Appsync latency
Dynamo stream latency
EventBridge Pipe duration
EventBridge Rules latency
The SQS time taken custom metric is calculated from SQS provided attributes.
Results
Disclaimer: some latency measurements are calculated on consumers' side, and we all know that synchronizing clocks in a distributed system is a hard problem.
Still, measurements are performed by the same computing nodes.
Please consider following latencies not as precise measurements but as coarse indicators.
Here screenshots from my Cloudwatch dashboard
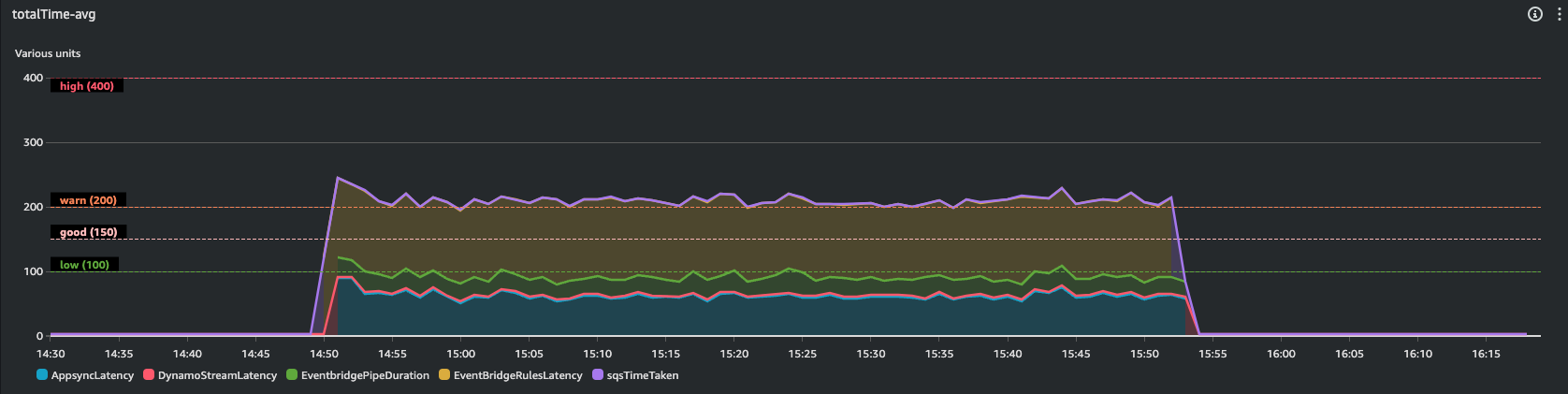
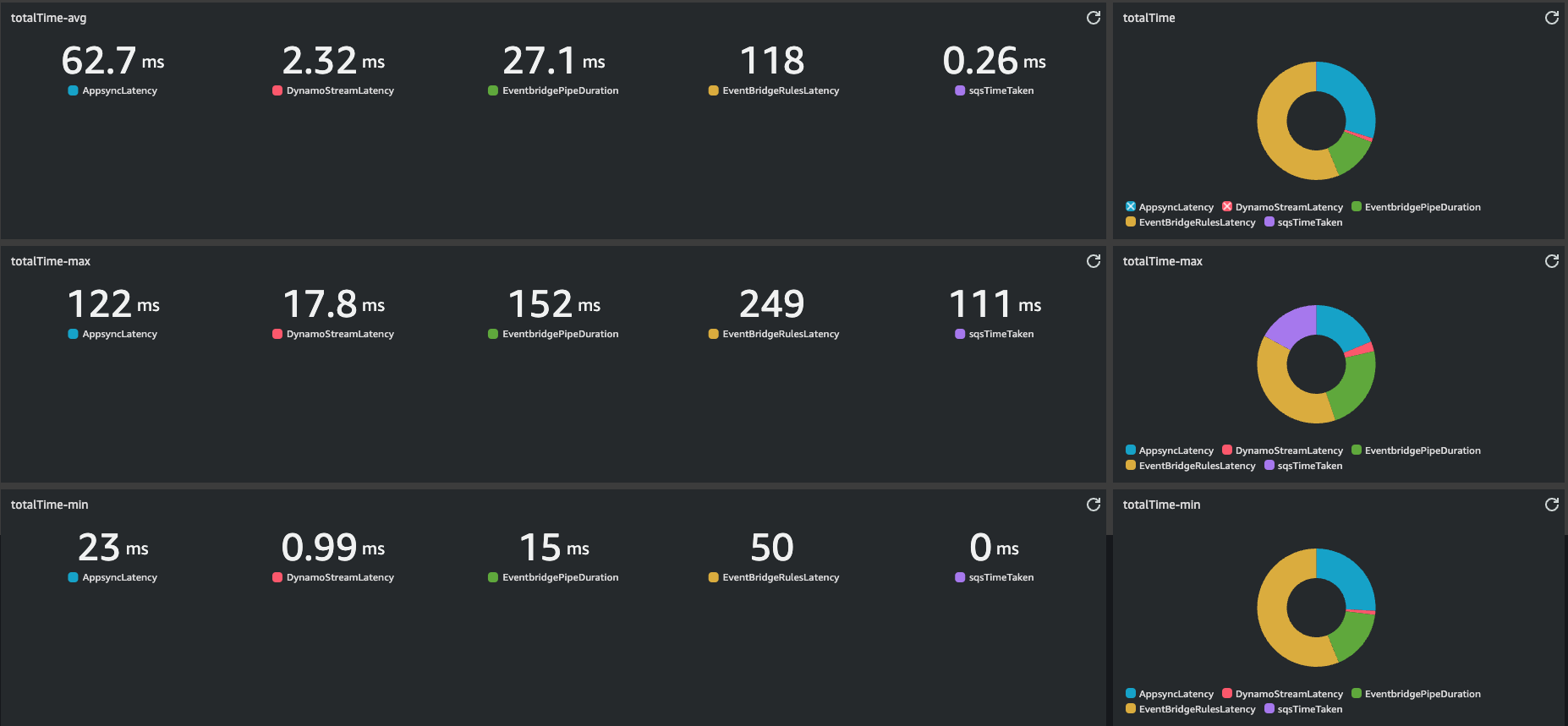
Few key data, from Average numbers:
Most of the time is taken by EventBridge rule, I couldn't do anything to lower this latency. The rule is as simple as possible and it is integrated natively by AWS.
The average total time taken is 210.74 ms, versus 108.39 ms taken by the first version with Lambda and SNS.
The average response time measured by my client, which covers my client's network latency, is 175 ms. Given Appsync AVG Latency is 62.7 ms, my Avg network latency is 112,13 ms. This means that from my client sending the mutation to consumers receiving the message there are 175 + 113.13 = 288.13 ms
Conclusion
This solution has proven to be fast and reliable and requires little configuration to set up and no glue-code to write.
Since everything is managed, there is no space for tuning and improvements.
The latency of this solution is worse than the first version by 194.44%.
However, EventBridge offers many more capabilities than SNS.
Wrap up
In this article, I have presented you with a solution that I had to design as part of my work and my approach to solution development: this includes clarifying the scope and context, evaluating different options, and having a good knowledge of the parts involved and the performance and quality attributes of the overall system, writing code and benchmarking where necessary, but always with the clear awareness that there are no perfect solutions.
I hope it was helpful to you, and here is the GitHub repo to deploy both versions of the solution.
Bye 👋!